The ultimate goal of the observation mechanism is to be able to know at all (or most) of the time what is the current manipulation process and what is the visual relationship between the hand and the object. The fact that the observer will have to move in order to keep track of the manipulation process, makes one think of the stabilizability principle for general DEDS as a model for the tracking technique that has to be performed by the observer's camera.
In real-world applications, many manipulation tasks are performed by
robots, including, but not limited to, lifting, pushing, pulling, grasping, squeezing, screwing and unscrewing of machine parts. Modeling all the possible
tasks
and also the possible order in which they are to be performed is possible to
do within a DEDS state model. The different hand/object visual relationships
for different tasks can be modeled as the set of states . Movements of
the hand and object, either as 2-D or 3-D motion vectors, and the positions
of the hand within the image frame of the observer's camera can be thought
of as the events set
that causes state transitions within the
manipulation process. Assuming, for the time being, that we have no direct
control over the manipulation process itself, we can define the set of
admissible control inputs
as the possible tracking actions that can be
performed by the hand holding the camera, which actually can alter the visual
configuration of the manipulation process (with respect to the observer's
camera). Further, we can define a set of ``good'' states, where the visual
configuration of the manipulation process enables the camera to keep
track and to know the movements in the system. Thus, it can be seen that
the problem of observing the robot reduces to the problem of forming
an output stabilizing observer (an observer that can always return to a set of ``good'' visual states)
for the system under consideration.
It should be noted that a DEDS representation for a manipulation task is by no means unique, in fact, the degree of efficiency depends on the designer who builds the model for the task, testing the optimality of a visual manipulation models is an issue that remains to be addressed. Automating the process of building a model was discussed in the previous section. As the observer identifies the current state of a manipulation task in a non ambiguous manner, it can then start using a practical and efficient way to determine the next state within a predefined set, and consequently perform necessary tracking actions to stabilize the observation process with respect to the set of good states. That is, the current state of the system tells the observer what to look for in the next step.
We present a simple model for a grasping task. The model is that of a gripper approaching an object and grasping it. The task domain was chosen for simplifying the idea of building a model for a manipulation task. It is obvious that more complicated models for grasping or other tasks can be built. The example shown here is for illustration purposes.
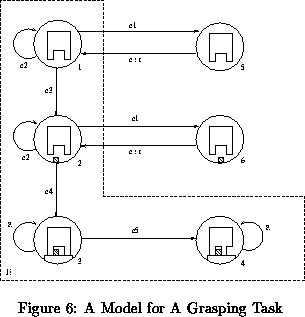
As shown in Figure 6, the model represents a view of the hand
at state 1, with no object in sight, at state 2, the object starts to
appear, at state 3, the object is in the claws of the gripper and at
state 4, the claws of the gripper close on the object. The view as presented
in the figure is a frontal view with respect to the camera image plane,
however, the hand can assume any 3-D orientation as so long as the claws
of the gripper are within sight of the observer, for example, in the case of
grasping an object resting on a tilted planar surface. This demonstrates the
continuous dynamics aspects of the system. In other words, different
orientations for the approaching hand are allowable and observable.
State changes occur only when the object appear in sight or when the hand
encloses it. The frontal upright view is used to facilitate drawing the automaton only.
It should be noted
that these states can be considered as the set of good states , since
these states are the expected different visual configurations of a hand
and object within a grasping task.
States 5 and 6 represent instability
in the system as they describe the situation where the hand is not
centered with respect to the camera imaging plane, in other words, the
hand and/or object are not in a good visual position with
respect to the observer as they tend to escape the camera view. These states
are considered as ``bad'' states as the system will go into a non-visual
state unless we correct the viewing position. The set is the finite set of states, the set
is the set of
``good'' states.
Some of the events are defined as motion vectors or motion vector probability
distributions, as will be described later, that causes state transitions and
as the appearance of the object into the viewed scene. The transition from
state 1 to state 2 is caused by the appearance of the object. The transition
from state 2 to state 3 is caused by the event that the hand has enclosed
the object, while the transition from state 3 to state 4 is caused by the
inward movement of the gripper claws. The transition from the set
to the set
is caused by movement of the hand as it escapes the
camera view or by the increase in depth between the camera and the viewed scene, that is, the hand moving far away from the camera. The self loops are caused by either the stationarity of the
scene with respect to the viewer or by the continuous movement of the hand
as it changes orientation but without tending to escape a good viewing position
of the observer. In the next section we discus different techniques to
identify the events. The controllable events denoted by ``
'' are the
tracking actions required by the hand holding the camera to compensate for the
observed motion. Tracking techniques will later be addressed in detail. All the
events in this automaton are observable and thus the system can be represented
by the triple
, where X is the finite set of states,
is the finite set of possible events and
is the set of admissible
tracking actions or controllable events.
It should be mentioned that this model of a grasping task could be extended
to allow for error detection and recovery. Also search states
could be added in order to ``look'' for the hand if it is no where in sight.
The purpose of constructing the system is to develop an observer for the automaton which will enable the determination of the current state of the system at intermittent points in time and further more, enable us to use the sequence of events and control to ``guide'' the observer into the set of good states and thus stabilize the observation process. Disabling the tracking events will
obviously make the system unstable with respect to the
set
(can't get back to it), however, it should be noted that the subset
is already stable with respect to
regardless of the tracking actions,
that is, once the system is in state 3 or 4, it will remain in
.
The whole system is stabilizable with respect to
,
enabling the tracking events will cause all the paths from any state to go
through
in a finite number of transitions and then will visit
infinitely often.